Data Lake Market Report Scope & Overview:
Get more information about Data Lake Market - Request Free Sample PDF
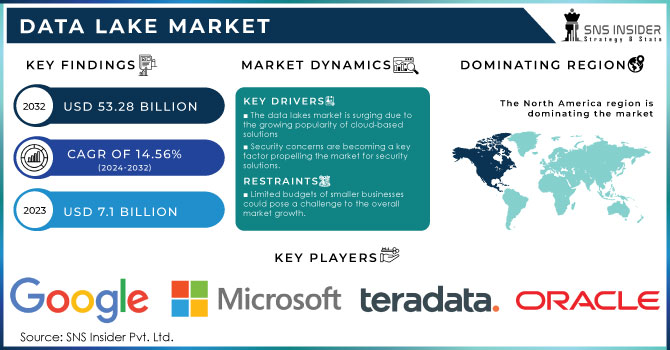
The Data Lake Market was valued at USD 9.44 billion in 2023 and is expected to reach USD 49.97 billion by 2032, growing at a CAGR of 20.39% over the forecast period 2024-2032.
Globally, the Data Lake Market is on the rise with massive installations essentially driven by huge enterprises' dependence on capacity and market costs for storing and streamlining multi-structured data. Companies generate a large amount of data, much of which is semi-unstructured or non-structural, from different sources, such as sensors and social media. Given that traditional data management structures and technologies cannot deal with such a high degree of data complexity and volume, companies are encouraged to transfer such data to a data lake. They help users interpret whether and how they would like to use these data through analytic and machine-learning technologies. One of the surged accessible applications has been data lakes. A total of 65% of organizations embraced data lakehouses for analytics in 2024, and 56% of organizations enjoyed more than a 50% savings on analytics costs. Almost 30% of large enterprises were able to save upwards of 75% Data mesh strategies were implemented by 84% of enterprises.
Advances in information technology and the advent of optically warned data lakes allow various IT, cell phone, and legislative industries to succeed in this business. In recent years, growing attention has been paid to pressure computing in the workplace. The surge in pressure technology helps boost the data lakes market with lower costs, higher elasticity, lower on-premises storage needs, and the evolving query operating performance of the data lake technologies. For organizations of all shapes and weights, highly efficient, cost-effective, and efficient cloud data lakes are essential. In addition, cloud-related data lakes boost their marketability with higher security measures. Overall, linked data lakes with all the data help produce additional complementary workloads for various businesses, significantly enhancing operational performance based on the datum. Cloud computing was present across 94% of enterprises in 2024, and multi-cloud environments for improving performance were used by 69% of organizations. Cloud data security continues to be an ongoing struggle, as a staggering 55% find it to be complex, while a staggering 57% claim they have low to medium confidence in their ability to secure data.
MARKET DYNAMICS
KEY DRIVERS:
-
Accelerating Business Growth with Real-Time Analytics and AI-Driven Insights through Data Lake Adoption
The high adoption of real-time analytics to accelerate the business decision-making process is one of the major factors that is likely to boost the growth of the Data Lake market and propel it to a new high. In terms of decision-making, modern organizations are transcending from the reactive to the proactive and predictive processes. To help make this transition, it means having real-time access to data streams that help you find trends, opportunities, and risks to respond to at the moment. Real-time insights play an important role in business applications across various industries such as retail, e-commerce, and energy (dynamic pricing, inventory management, predictive maintenance, etc.). By being able to ingest and process data from multiple sources at the same time, data lakes, provide the foundation for real-time analytics, which allow for continuous business flexibility and competitiveness in rapidly changing business environments. In 2024, 75% of businesses adopted AI-driven analytics, with 80% reporting revenue growth. Companies leveraging advanced data analytics are 23 times more likely to acquire customers and 19 times more likely to profit.
-
Leveraging IoT Data to Drive Operational Efficiency and Innovation through Scalable Data Lake Solutions
The increasing proliferation and digitization of Internet of Things (IoT) devices and the massive expansion of data that is a byproduct is yet another key catalyst. The huge amount of data created by the increase of connected devices across all industries from smart home appliances and wearables to industrial sensors and autonomous vehicles. Such huge data which includes semi-structured or unstructured data need a powerful storage and processing solution to provide an easy way of storage and analysis. IoT is a key vertical for data lakes as they provide the scalability, and capability to handle the volume, velocity, and variety of IoT data fueling use cases such as smart city, precision agriculture, and industrial automation. The process of driving efficiencies, enhancing customer experiences, and creating new services all initiatives that can be bolstered by IoT data used to populate data lakes is another aspect fueling demand for data lakes. Daily, there are 402.74 million terabytes of data generated with the aid of IoT devices, By 2025, the industrial IoT space will be responsible for generating 79.4 zettabytes of data and as much as 83% of organizations using IoT data for operational decision-making. Moreover, 74% claim that operational efficiency has improved after the use of IoT data in data lakes.
RESTRAIN:
-
Overcoming Data Governance Challenges and Skill Shortages in Managing Complex Data Lake Architectures
One of the significant restraints in the Data Lake market is the complexity of data management and governance. Since data lakes frequently contain enormous amounts of raw and unstructured data, the latter should be properly organized, accessible, and high quality. Without adequate data governance frameworks, organizations may encounter such problems as data silos, duplication, and inconsistencies, which adversely affect analytical outcomes and decision-making. In addition, managing metadata and ensuring compliance with data privacy and other laws, such as GDPR and HIPAA, present multiple challenges for organizations, adding to the complexity of data governance. Another challenge related to the lack of adequate data management is the shortage of professionals capable of dealing with and optimizing data lake architectures. To be built, managed, and used properly, data lakes require a great deal of expertise in big data, machine learning, and data engineering, and many organizations find it challenging to keep personnel with these highly specialized skills.
SEGMENTS ANALYSIS
By Business Function
In 2023, the Marketing function accounted for the majority segment of the Data Lake market and held a share of 35.7% as it is essential for customer engagement and helps in growing the business. All marketing organizations depend on data lakes to process customer data collected from various sources, like websites, CRM systems, and social media, to analyze customer preferences. With data lakes, marketing teams can conduct real-time analytics, better segment customers, and execute personalized marketing. Structured and unstructured data integration allows businesses to optimize campaigns, enhance customer acquisition, and maximize ROI, making marketing the biggest segment in the Data Lake market.
HR segment to remain one of the fastest growing in terms of CAGR during the period 2024-2032. HR departments are using data lakes to assess trends in employee performance, engagement, and retention, and using predictive analytics and AI to optimize recruitment processes. The rise of innovative tools for employee analysis, diversity management, and skill gap analyses is now pushing the requirement for powerful data storage and processing capabilities. There is a push toward data-driven or evidence-based HR practices, and this is what is driving the adoption of data lakes at a breakneck speed in the HR space.
By Deployment
On-premise deployment held the largest market share of 62.2% in 2023, continuing to be the preferred delivery option in the Data Lake market, as several industries still need strict control over their data possession process. Industries like BFSI, healthcare, and government organizations deal with the most private information, hence, security and compliance with stringent regulations are a must. These organizations are more comfortable having their own solution where they control their entire data infrastructure, which in turn makes it safer, more customizable, and more compliant with regulations. Further, massive enterprises with established capital invested in on-premise IT systems still use these services for smooth interaction with functionality.
On-Cloud deployment is expected to grow at the highest CAGR during 2024-2032 owing to the increasing requirements for scalability, cost-effective pricing, and accessibility. Data lakes based in the cloud provide the luxury of unlimited storage of huge data, quickly processing any kind of data without the need to purchase hardware in advance this could also be especially attractive to small and medium businesses (SMEs). Also, due to developments in the cloud security sector (along with other functionalities such as real-time analytics, automated updates, and multi-region availability), the worries about security are disappearing. With the rise of hybrid cloud strategies and the increased availability of pay-as-you-go pricing models, on-cloud data lake solutions are seeing a rapid increase in adoption as businesses look to achieve agility and innovation in a competitive landscape.
By Enterprise Type
Large Enterprises accounted for the largest Data Lake market with a 71.7% share in 2023 driven by high data requirements along with the availability of infrastructure & technology. From customer interactions to operational systems and supply chains, these entities produce enormous quantities of structured, semi-structured, and unstructured data from various sources. To store and analyze such a huge amount of data companies need scalability and flexibility, and Data lakes provide the move of large enterprises to actionable insights, which is the Competitive Edge. In addition to that, established organizations have deep pockets to invest in sophisticated data lake technologies as well as some skilled professionals resulting in stronger market dominance.
The Small and Medium-Sized Enterprises (SMEs) segment is anticipated to register the fastest CAGR from 2024-2032 as the deployment of cloud-based data lake solutions at economical prices has become more accessible. More and more SMEs are realising the importance of using data-driven decision-making to increase efficiency and customer engagement. The evolution of cloud-based data lake models, where players only pay for the resources they use, reduces infrastructure overhead and creates avenues for businesses with smaller operational scales to access advanced analytics capabilities. They are also using data lakes for personalization, operational optimization, and customer segmentation in SME use cases as well. The increasing data lake solutions adoption trend among SMEs due to the global digital transformation will propel SMEs in the data lake market.
By End-Use
IT & Telecom is leading the Data Lake market with the highest market share of 28.3% in 2023 due to the extremely large amount of data generated from various operations in the industry such as network operations, customer interaction, and service usage. Telecom companies create a huge volume of structured and unstructured data such as call logs, customer behavior, and service performance metrics which can be stored and analyzed in data lakes. This market space has seen the boom of data lake solutions based on the demand for real-time analytics, predictive maintenance, and improvement of customer experiences.
Retail & E-commerce is forecasted to register the fastest CAGR for the 2024-2032 period, attributed to rising demand for data in creating personalized customer experiences, managing inventory, and using targeted marketing. Data lakes are being used by retailers to merge customer information from different touchpoints: online shopping, in-store shopping, or social media platforms. Across omnichannel strategies, being able to process and analyze massive amounts of data in short order is critical to understanding consumer choices and optimizing operations. As this trend continues to grow within the retail sector, it is anticipated that a continuous market expansion will shortly see the rapid adoption of data lakes in the industry.
REGIONAL ANALYSIS
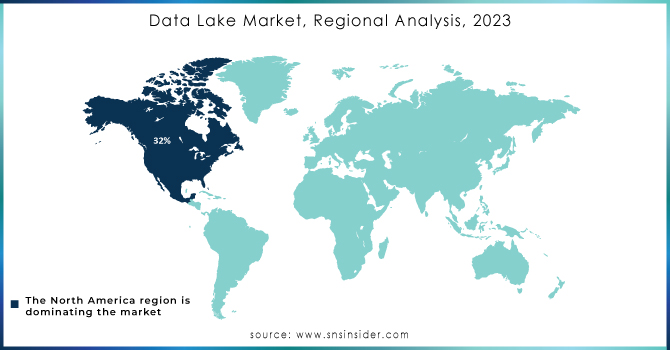
North America held the highest Data Lake market share, accounting for 35.7% in 2023, owing to well-established technical infrastructure, high cloud service acceptance, and digital transformation across end-use sectors in the region. For example, some of the largest tech companies and data-generating enterprises like Amazon, Google, and Microsoft are located in the US. These organizations use data lakes in order to utilize big data to improve processes, provide better customer experiences, and help innovate with AI-powered insights. Example: Amazon Amazon is known to leverage a lakehouse architecture to handle the colossal volumes of data produced by its e-commerce platform, supply chain, and AWS cloud services to improve business decisions and provide tailored recommendations to its users. Likewise, "Netflix" uses the Data Lark to scale great part data preparing for content suggestions, user conduct diagnostics, and streaming quality optimization.
Asia Pacific is projected to grow at the fastest CAGR during 2024-2032, owing to fast digitalization, rising cloud technologies adoption levels, and the increasing focus on big data analytics in developing countries, including China, India, and Japan. All of the points are that, in China Alibaba Cloud provides data lake solutions that streamline data management and analytics for enterprises and e-commerce on its e-commerce and cloud services platforms, delivering solutions that accommodate massive amounts of customer, product, and transaction data. It enables organizations to make data-driven decisions, optimize logistics, and customize customer experiences. One of the biggest e-commerce platforms in India, Flipkart uses data lakes to analyze customer behavior data to improve product recommendations, inventory management, and marketing strategies. The Asia Pacific region is expected to be a critical driver of growth in the global data lake market, as these regions move toward digitization and invest in AI and machine learning technologies.
Need any customization research on Data Lake Market - Enquiry Now
KEY PLAYERS
Some of the major players in the Data Lake Market are:
-
Microsoft Corporation (Azure Data Lake Storage, Azure Synapse Analytics)
-
Amazon Web Services (AWS) (Amazon S3, AWS Lake Formation)
-
Cloudera, Inc. (Cloudera Data Platform, Cloudera DataFlow)
-
Oracle Corporation (Oracle Cloud Infrastructure Data Lakehouse, Oracle Big Data Service)
-
Teradata Corporation (Teradata Vantage, Teradata IntelliCloud)
-
IBM Corporation (IBM Cloud Pak for Data, IBM Watson Knowledge Catalog)
-
Informatica Corporation (Informatica Intelligent Data Lake, Informatica Data Engineering Integration)
-
SAS Institute Inc. (SAS Data Management, SAS Viya)
-
Snowflake Inc. (Snowflake Data Cloud, Snowflake Data Marketplace)
-
Google LLC (Google Cloud Storage, BigQuery)
-
Dremio Corporation (Dremio Data Lake Engine, Dremio Arctic)
-
Zaloni, Inc. (Zaloni Arena, Zaloni Data Catalog)
-
Hewlett Packard Enterprise (HPE) (HPE Ezmeral Data Fabric, HPE GreenLake)
-
Accenture (Accenture Insights Platform, Accenture Data Platform)
-
Capgemini SE (Capgemini Insights & Data, Capgemini Data Lake Accelerator)
-
Google Cloud Platform (Google Cloud Storage, Google BigQuery)
-
Dell Technologies (Dell EMC Elastic Cloud Storage, Dell EMC Isilon)
-
SAP SE (SAP Data Intelligence, SAP HANA)
-
Hitachi Vantara (Hitachi Content Platform, Pentaho Data Integration)
-
Qlik Technologies (Qlik Data Integration, Qlik Sense)
Some of the Raw Material Suppliers for Data Lake Companies:
-
Intel Corporation
-
Advanced Micro Devices (AMD)
-
NVIDIA Corporation
-
Broadcom Inc.
-
Samsung Electronics Co., Ltd.
-
Micron Technology, Inc.
-
Seagate Technology Holdings PLC
-
Western Digital Corporation
-
Cisco Systems, Inc.
RECENT TRENDS
-
In December 2024, Amazon S3 introduced new features, including S3 Tables for optimized analytics and S3 Metadata for easier data discovery and management, enhancing its data lake capabilities.
-
In March 2024, Cloudera unveiled the next phase of its open data Lakehouse, enhancing customer data utilization to unlock enterprise AI capabilities. The updates include new features like Apache Iceberg for private clouds and security enhancements for better scalability and efficiency.
-
In September 2024, Oracle launched the Intelligent Data Lake and introduced generative AI-powered analytics within its Oracle Data Intelligence Platform, enhancing data orchestration and governance.
| Report Attributes | Details |
|---|---|
|
Market Size in 2023 |
USD 9.44 Billion |
|
Market Size by 2032 |
USD 49.97 Billion |
|
CAGR |
CAGR of 20.39% From 2024 to 2032 |
|
Base Year |
2023 |
|
Forecast Period |
2024-2032 |
|
Historical Data |
2020-2022 |
|
Report Scope & Coverage |
Market Size, Segments Analysis, Competitive Landscape, Regional Analysis, DROC & SWOT Analysis, Forecast Outlook |
|
Key Segments |
• By Business Function (Marketing, HR, Operations, Finance) |
|
Regional Analysis/Coverage |
North America (US, Canada, Mexico), Europe (Eastern Europe [Poland, Romania, Hungary, Turkey, Rest of Eastern Europe] Western Europe] Germany, France, UK, Italy, Spain, Netherlands, Switzerland, Austria, Rest of Western Europe]), Asia Pacific (China, India, Japan, South Korea, Vietnam, Singapore, Australia, Rest of Asia Pacific), Middle East & Africa (Middle East [UAE, Egypt, Saudi Arabia, Qatar, Rest of Middle East], Africa [Nigeria, South Africa, Rest of Africa], Latin America (Brazil, Argentina, Colombia, Rest of Latin America) |
|
Company Profiles |
Microsoft Corporation, Amazon Web Services, Cloudera, Inc., Oracle Corporation, Teradata Corporation, IBM Corporation, Informatica Corporation, SAS Institute Inc., Snowflake Inc., Google LLC, Dremio Corporation, Zaloni, Inc., Hewlett Packard Enterprise, Accenture, Capgemini SE, Google Cloud Platform, Dell Technologies, SAP SE, Hitachi Vantara, Qlik Technologies |
|
Key Drivers |
• Accelerating Business Growth with Real-Time Analytics and AI-Driven Insights through Data Lake Adoption |
|
RESTRAINTS |
• Overcoming Data Governance Challenges and Skill Shortages in Managing Complex Data Lake Architectures |
Frequently Asked Questions
Ans: The Data Lake Market is expected to grow at a CAGR of 20.39% during 2024-2032.
Ans: Data Lake Market size was USD 9.44 billion in 2023 and is expected to Reach USD 499.30 billion by 2032.
Ans: The major growth factor of the Data Lake market is the increasing volume and complexity of data being generated, driving the need for scalable and flexible storage and analytics solutions.
Ans: The On-Premise segment dominated the Data Lake Market in 2023.
Ans: North America dominated the Data Lake Market in 2023.
Get in Touch
