Synthetic Data Generation Market Report Scope & Overview:

Get more information on Synthetic Data Generation Market - Request Sample Report
The Synthetic Data Generation Market size was USD 0.29 billion in 2023 and is expected to reach USD 3.79 billion by 2032 and grow at a CAGR of 33.05% over the forecast period of 2024-2032.
The rise of machine learning models and AI systems, the need for diverse, high-quality data is becoming more and more crucial. These models require large and varying datasets to learn and become more efficient and productive. In some cases, however, it might be difficult or even impossible to obtain such data. Real data can be restricted and difficult to get access to, or collecting it might be too expensive in some cases. Synthetic data was developed to address these limitations. It allows generating artificial pseudo-datasets, which simulate regular data while having minimal to no restrictions.
Moreover, synthetic data offers numerous scenarios and variations, from which it is easy to generate a dataset. Overall, synthetic data is useful in scenarios where obtaining real data might be problematic. Proper access to synthetic data makes it easier to generate high-quality datasets, train AI models, and test them in different conditions.
For instance, in 2023, Google introduced "Synthetic Data for ML Models", a new tool aimed at enhancing data privacy and enabling more effective training of machine learning models. This tool leverages Google's advanced algorithms to generate synthetic datasets that preserve the statistical properties of real data while protecting individual privacy.
Moreover, the considerable importance and role of the Internet of Things and the Industrial Internet of Things for the production of actual technologies and algorithms will gradually expand. It was interesting for me to learn that future IoT/IIoT applications will involve many AI techniques, including machine learning and neural networks. Another interesting fact is that there will be devices that will help optimize information processing, specifically drones, robotic devices, augmented reality, and autonomous vehicles.
MARKET DYNAMICS
Drivers
Increasing demand for data security and privacy, and rising investment in advanced technologies drive the market growth.
The synthetic data generation market shows promising dynamics owing to an escalating demand for securing data and an upsurge of investments in advanced data technologies. Modern companies pay many concerns to the protection of the customers’ data, especially nowadays, with a growing number of data leaks. Synthetic data, or artificially created data that resembles real-world data, is the optimal solution to the predicament as organizations can test drive algorithms, train machine-learning algorithms, and execute analytics without using private or sensitive data. As a result, there are reduced security risks and minimized issues that arise when handling real data.
Moreover, a significant driver of the market has become advanced data technologies, as Artificial Intelligence and Machine Learning technologies are often used by businesses to process the data. These technologies require vast volumes of data to become more accurate sight. Consequently, synthetic data remains a critical aspect of the technology, as it becomes a cost-efficient and easily scalable alternative. It is possible to expect that the demand for and offer of solutions that maintain sophisticated data systems is going to rise, and the Synthetic Data Generation Market is anticipated to grow in the upcoming future.
Restrain
Synthetic data generation often relies on high-end generative models which hamper market growth.
Synthetic data generation, a rapidly evolving field, often relies on high-end generative models like Generative Adversarial Networks and Variational Autoencoders. While these advanced models have the potential to create realistic and useful synthetic datasets, they can also impede market growth due to several factors. It is due to complexity and computational demands of these models require significant investment in high-performance hardware and expertise, which can be prohibitive for smaller organizations or startups.
OPPORTUNITY
-
It creates Opportunity in Data analytics and visualization.
-
Synthetic data can be used to create new revenue streams by selling datasets to third-party organizations
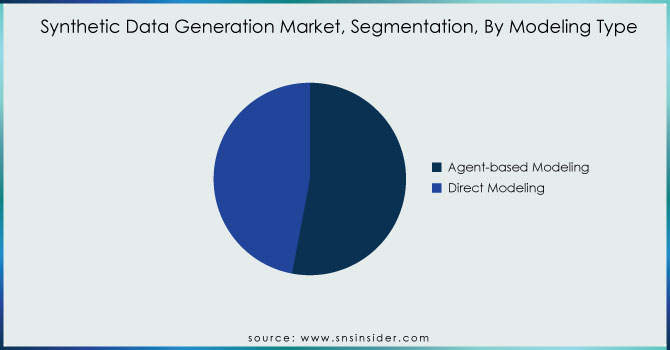
By Modeling Type
The agent-based modeling segment held the largest market share around 60% in 2023. Agent-based modeling is gaining traction for creating a physical model of real-world data and reproducing data using the same model. Recently, agent-based modeling has gained preference over traditional models in finance. It is very popular in generation of business transactions for testing and developing fraud detection systems. Industry participants are anticipated to rely on ABMs to exploit the modeling of all sorts of networks. ABMs have gained favor in simulating consumer interactions, innovations, autos, and roads.
Need any customization research on Synthetic Data Generation Market - Enquiry Now
By Offering
The trend of fully synthetic data continues to dominate the market with the largest revenue share of 36.23% in 2023. However, the presence of the second largest revenue share by the hybrid synthetic data segment will record a remarkable CAGR during the forecast period. The hybrid synthetic data segment is attributed to privacy preservation with increased utility as it avails 100% and partially synthetic data. This trend for hybrid synthetic data will be relatively visible across end-use sectors, increased processing time may crumble the market moving forward.
By Application
In 2023 the natural language processing segment accounted for over 28% of the market share. One of the main drivers for the exponential use of synthetic data in the field is that it helps bootstrap the next generation of language releases. In September 2023 Amazon easternon consumers in the U.S., U.K., Germany, and Japan with the launch of its Echo Show and Alexa mobile app. Probably one of the main attractions the company has in promoting the use of synthetic data in the completion and streamlining of the training data of its natural language understanding systems.
By End-Use
The healthcare & life sciences portion represented the largest share in terms of revenue, 24 percent, in 2023. The growing demand for privacy-preserving synthetic data is projected in the healthcare & life science sector. Data breach risks, patient privacy, the regulatory landscape, separate data sources, synthetic data, and artificial data generation tools have all piqued the most attention. For example, in May 2022, Anthem Inc. and Google Cloud, a subsidiary of Alphabet Inc., formed a partnership to create 1.5 to 2 petabytes of synthetic data to improve fraud detection and enhance relevant services for patients and providers. The strong potential of synthetic data in healthcare, combined with the industry’s rapidly evolving privacy regulations, will serve to further solidify the leadership of leading companies in the global market.
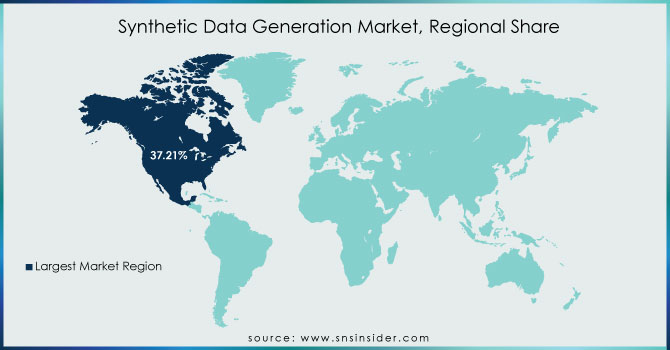
REGIONAL ANALYSIS
North America held the highest market share in the synthetic data generation market around 37.21% in 2023. This is Due to end-use sectors' growing interest in fraud detection, NLP, and image data, the United States and Canada have emerged as profitable locations. Several businesses have increased their investments in synthetic data, including J.P. Morgan, American Express, Amazon, and Google's Waymo. For example, Amazon launched Amazon Sage Maker Ground Truth in June 2022 to create labeled synthetic image data. These market participants will exhibit a preference for artificial data to train machine learning, payment data to detect fraud, and anti-money laundering behaviors. the growing influence of computer vision will also do well in the prediction for the synthetic data production industry in North America. Physical security, manufacturing, and geospatial imagery have all gained significant interest.
KEY PLAYERS
The major key players in the Synthetic Data Generation Market are Amazon.com, Inc., Microsoft Corporation, Gretel Labs, YData, Mostly AI, DataGen Technologies, NVIDIA Corporation, CVEDIA Inc., Synthesis AI, IBM Corporation, MDClone and other players.
RECENT DEVELOPMENTS
Microsoft:
In January 2023, Microsoft entered into a multi-billion-dollar partnership with OpenAI to accelerate the development of AI technology. The partnership aims to democratize AI and make it accessible to everyone. The partnership has already yielded impressive results, including the development of GPT-3
Databricks:
In May 2023, Databricks acquired Okera, a data governance platform with a focus on AI. the acquisition will enable Databricks to expose additional APIs that its own data governance partners will be able to use to provide solutions to their customers.
| Report Attributes | Details |
| Market Size in 2023 | USD 0.29 bn |
| Market Size by 2032 | USD 3.79 bn |
| CAGR | CAGR of 33.05% From 2024 to 2032 |
| Base Year | 2023 |
| Forecast Period | 2024-2032 |
| Historical Data | 2020-2022 |
| Report Scope & Coverage | Market Size, Segments Analysis, Competitive Landscape, Regional Analysis, DROC & SWOT Analysis, Forecast Outlook |
| Key Segments | • By Data Type (Tabular Data, Text Data, Image & Video Data, and Others (Audio, Time Series, etc.)) • By Modeling Type (Direct Modeling and Agent-based Modeling) • By Offering (Fully Synthetic Data, Partially Synthetic Data, and Hybrid Synthetic Data) • By Application (AI/ML Training and Development, Test Data Management, Data Protection, Enterprise Data Sharing, Predictive Analytics, Natural Language Processing, Computer Vision Algorithms, and Others) • By End-use (BFSI, Healthcare & Life Sciences, Transportation & Logistics, IT & Telecommunication, Retail and E-commerce, Manufacturing, Consumer Electronics, Government & Defense, and Others) |
| Regional Analysis/Coverage | North America (US, Canada, Mexico), Europe (Eastern Europe [Poland, Romania, Hungary, Turkey, Rest of Eastern Europe] Western Europe] Germany, France, UK, Italy, Spain, Netherlands, Switzerland, Austria, Rest of Western Europe]). Asia Pacific (China, India, Japan, South Korea, Vietnam, Singapore, Australia, Rest of Asia Pacific), Middle East & Africa (Middle East [UAE, Egypt, Saudi Arabia, Qatar, Rest of Middle East], Africa [Nigeria, South Africa, Rest of Africa], Latin America (Brazil, Argentina, Colombia Rest of Latin America) |
| Company Profiles | Amazon.com, Inc., Microsoft Corporation, Gretel Labs, YData, Mostly AI, DataGen Technologies, NVIDIA Corporation, CVEDIA Inc., Synthesis AI, IBM Corporation, MDClone |
| Key Drivers | • The market for synthetic data production has new growth potential due to the rising demand for IoT and connected devices. • Increasing demand for data security and privacy, rising investment in advanced technologies drive the growth of the market. |
| Market Restraints | • Synthetic data generation often relies on high-end generative models. |
Frequently Asked Questions
Ans. The ethical considerations surrounding the use of synthetic data emphasize the importance of fairness, privacy, transparency, and accountability. It is essential to address these considerations throughout the entire lifecycle of synthetic data, from its creation to its use in various applications.
Ans. Generating Data According to a Known Distribution, Fitting Real Data to a Distribution, Neural Network Techniques, Synthetic Image Generation with Variationally Autoencoders, Synthetic Image Generation with Generative Adversarial Network. These techniques provide different approaches to generating synthetic data that mimics the statistical properties and characteristics of real data.
Ans. Amazon.com, Inc., CVEDIA Inc., Datagen, IBM Corporation, Meta, Microsoft Corporation, Mostly AI, NVIDIA Corporation Synthesis AI and others.
Ans: The Synthetic Data Generation Market size was valued at US$ 0.2 million in 2023.
Ans. The Synthetic Data Generation Market is to grow at a CAGR of 36% over the forecast period 2024-2032.
Get in Touch
